Which is more important for SEO, building links from other sites or building relevant content and internal links within your own website to develop authoritative topicality and rankings?

Content and Internal Links or Inbound Links? Which Matters More?
Does building links for search engine optimization always imply getting other sites to link to yours or the target site in question? Not, necessarily.
When PageRank was first created as the Backrub algorithm, link citation was heavily weighed in the algorithm as a primary ranking factor, that was until spammers figured that out and the free for all link fest was in full effect.
This in turn made engineers reciprocate with other additional layers which looked for signals of trust and authority (such as the Hilltop algorithm) which works much like a third party referral system.
If your website is vouched for from the co-citation of authoritative websites or documents which have been deemed worthy, then your site would inherit ranking factor from the authority of the site that vouched for you. This algorithm relied primarily on semantic clusters and authority.
But, the real question is, how is that authority developed?
1. From volumes of themed content within a site.
2. links from sites with a high threshold of trust / reference or backlinks that embrace related keywords and key phrases.
3. From sites linking within their own body of documents to establish a preferred pecking order for semantic nodes.
If you truly understand what is implied, you can tactfully add content using inherent language from a theme that acts as the thread that connects the documents to a topical body of information.
Search engines do search for any occurrence of two or more words the based on inverse document frequency assign weighting mechanisms based on proximity and occurrence to decide the degree of relevance the local and global page exhibit and then assign a score.
This score is then used as an earmark / benchmark quota for relevancy in context to other documents within the index. Based on the “search” and the keyword or key phrase combination used, the search engine index is parsed and through a process of elimination removes eliminates pages with the least amount of significance, until it finds the nearest neighbor that squares the various metrics of the semantic and authoritative qualities of the combined search query.
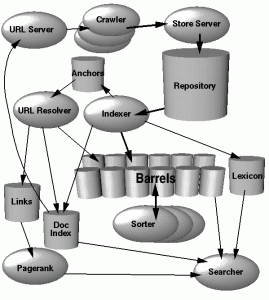
The Search Process
There is no need to overdo it, if you have relevant content on your page or within your website in either exact match or broad match form (such as one keyword in the title, another in a meta tag and another in a link to your site) the cross referenced metrics of relevance all contribute to providing a signifying assessment of relevance score.
Every change is logged from the time you create a page over the history of the document as it exists online. From the initial debut to present, cloud data and repositories have ghost images of your content from every page, every link ever built to and from it, every title change, or meta tag change which either increases its relevancy or decreases it based on which keyword or key phrase is queried through the vacuum when a search is conducted.
Not that this is occurring in real time, but rather based on the various layers of crawlers, the url server, the store server, repository, links, data centers and clouds that exist that have captured some form of your content in links, an RSS feed, on another site, referenced in social media or even on another server in a far away country. All of these metric are calculated when a search fetches a reference of your page or pages for a specific keyword or key phrase.
Also, keep in mind that as search behavior shifts, so do the term weights and their significance, so many searches or keywords that were hot once upon a time and now relegated to the supplemental index since their demand and frequency may have diminished.
All of these “impressions” that fulfilled queries made to reach your website add up (like a huge server log which can be compressed, stored, parsed and cross-referenced) and contribute to your websites unique digital footprint.
This footprint in turn dictates the degree of authority and trust contained within your pages and their ability to pass ranking factor to your own site, other sites or act as online hubs for topical data.
So, to go back to the notion of rankings, it’s not always about links, it is about proximity, and how concentrated your content and keyword and link citations are (both within a site and from other sites linking to it) that determine how much regard it has for any given search term.
If enough sites link to you with the word blue widgets and you sell red widgets, you will eventually rank for blue and red widgets, even if you only have the word red buried deep within the site out of context.
Every page in your site is calculated in a moments notice and either elevates your site or page as a relevant hit or dismisses it based on lack of contextual relevance to the query at hand.
Another thing to consider, its not always about backlinks (especially after domain authority has kicked in). For every 1000 to 1500 words of topical content, this is equivalent to a strong backlink to your site from a trusted authority.
Granted if the content is connected in tandem with other themed documents via internal links, navigation, sub folders or subdomains, etc.Just think of the Wikipedia effect on a smaller scale.
So, now you can understand the correlation of websites with thousands of pages and how they are easily able to rank for keywords sparsely mentioned or easily rank for keywords that have a high level of frequency within the site.
Combine that with the ever expanding nature of the web, and everyone’s content churning at extreme rates and the query itself (which are just often more unique than we imagine) are capable of cuing long-tail derivatives from ghost data, supplemental indexes as fresh crawl data.









Nice post.. Here is my blog about link building..Link building is one of the SEO solutions that help in providing high search engine page ranking. Learn link building strategies to propel your site to top of the search engines..
Link Building improves the Search Engine Ranking of your web page if done in specific ways.Besides an improved Search Engine Ranking, there are certain other benefits that your website derives from carrying out a Link Building Campaign.
Check some useful tips for link building
http://tinyurl.com/ydz3lv9
Internal linking is used for to (a) spread your pagerank around your website and (b) help search engines figure out what individual pages are about. It’s also necessary to help visitors navigate your website. Think about anchor text for internal links too: Many people send hours creating the perfect anchor text to use for their back-link generation processes. Then, they completely ignore the anchor text on their own website. Both are important. Paying more attention to the anchor text used for internal links can help both users and Google navigate your site better.
If you’re looking for a good introduction to SEO guideline that an economical SEO firm can follow, check this one out. http://www.bergstrom-seo.com/resources/google-search-engine-optimization-starter-guide.pdf. It was written by google, and it’s really good.
Link Building or Topical Content and Internal Links?
Thanks for sharing!
Great Info! Thanks for the post!
You have a broken link, towards the top of this poast:
Anchor-Text:(Hilltop algorithm)